/https://www.webnews.it/app/uploads/2014/03/proposal1.jpg "La proposta di Tim Berners-Lee: così nasce il Web")
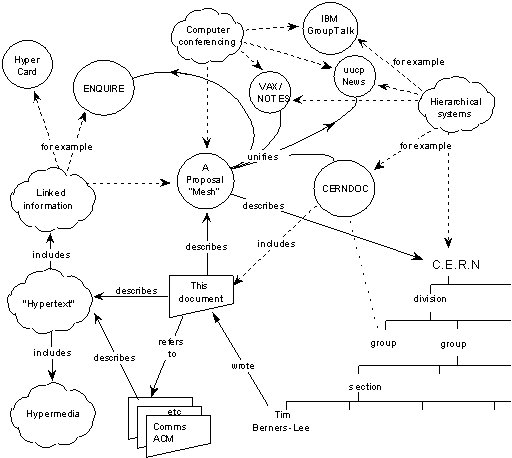
Il 12 marzo 1989 Tim Berners-Lee ha presentato al cospetto di Mike Sendall il seguente schema raffigurante quella che era l’idea alla base del World Wide Web (il cui nome sarà coniato però soltanto qualche mese più tardi):
La proposta di Tim Berners Lee
Fredda, ma incuriosita, la reazione di Mike Sendall: “vago, ma interessante“. Il resto è storia.
La proposta di Tim Berners-Lee
Il documento originale non è più disponibile, ma in varia forma è reso oggi reperibile grazie al sito W3.org che ne ha garantita la sopravvivenza dei contenuti nel tempo.
L’introduzione esplicita quelle che sono le finalità preposte al progetto: «discute il problema dell’accesso delle informazioni al CERN». Inoltre, propone una soluzione al problema medesimo: un sistema di link tra le informazioni che generi una struttura non lineare in sostituzione del precedente metodo lineare di accesso alle stesse. Nella sua disamina, Tim Berners Lee parte dalla metafora del libro, evidenziando come non si possa aggiornare il libro che racchiude tutto il sapere del CERN ogni qualvolta c’è una nuova scoperta. Occorre dunque arrivare a un metodo più flessibile e di più facile gestione, nel quale si possa modificare una singola parte del tutto senza per questo compromettere né dover metter mano a tutto il resto.
L’analisi di Tim Berners-Lee affronta quindi i problemi degli schemi ad albero, ove il legame genitore-figlio diventa un limite nel momento in cui lo schema strutturale delle informazioni è invece ben più complesso. Nemmeno le keyword sono però un viatico percorribile, poiché occorre fare un passo ulteriore e più radicale. Nasce così l’idea di applicare il concetto di ipertesto all’organizzazione delle informazioni del CERN prima e del resto del mondo poi. L’ipertesto (concetto già noto) applicato su più ampia scala, nella convinzione per cui possa restituire sinergie crescenti a mano a mano che si aggiungono informazioni e utenti al sistema.
La soluzione è l’ipertesto
Tim Berners-Lee spiega nella propria proposta di aver realizzato già nel 1980 un software di nome Enquire che consentiva di mettere in relazioni singole porzioni di informazione su documenti differenti. Non solo: il sistema era pensato per consentire l’accesso alle medesime risorse da parte di più persone, esattamente quel di cui il CERN abbisogna per rendere più facilmente reperibile, aggiornabile ed utilizzabile la quantità di informazioni archiviata durante le ricerche.
TBL non nasconde il vantaggio di poter sedere sulle spalle dei giganti: grazie alle intuizioni di Vannevar Bush, Ted Nelson e altri visionari dei decenni precedenti, nel 1994 il concetto di ipertesto era ormai maturo per essere applicato in nuovi campi e per nuove ambizioni. Ma il “plus” di Tim Berners-Lee arriva a stretto giro di posta: in poche righe vengono snocciolati veri e propri archetipi sui quali il Web è stato successivamente sviluppato: la possibilità di accesso da remoto ai file, l’eterogeneità dei sistemi di accesso, la non-centralizzazione dell’intera struttura, l’idea per cui i link vadano considerati come materia viva e cangiante.
Ulteriori considerazioni firmate da Tim Berners-Lee riguardano la navigazione tra le informazioni, la possibilità di accedere in parallelo ai medesimi server ed altri dettagli che già delineavano la prossima realizzazione del progetto. TBL chiedeva a Mike Sendall 6-12 mesi di tempo e 1-2 persone al lavoro sulla questione. Oggi in quel progetto ci sono miliardi di persone. E il Web ha ormai 25 anni.
/https://www.webnews.it/app/uploads/2025/04/wp_drafter_1212705.jpg)
/https://www.webnews.it/app/uploads/2025/04/wp_drafter_1212643.jpg)
/https://www.webnews.it/app/uploads/2025/04/wp_drafter_1212503.jpg)
/https://www.webnews.it/app/uploads/2025/04/wp_drafter_1212427.jpg)