/https://www.webnews.it/app/uploads/2017/07/speech.jpg "Da audio a video: è possibile (e spaventoso)")
Prima di leggere il resto dell’articolo si consiglia di guardare la clip in streaming di seguito, poi di tornare a queste prime righe. Stupirà sapere che la versione di Obama nel riquadro a destra non è reale. In estrema sintesi, si tratta di un video ottenuto dalla conversione di un file audio. È il frutto del lavoro portato avanti da alcuni ricercatori della University of Washington.
Synthesizing Obama
Il progetto, proprio per l’impiego dell’ex presidente degli Stati Uniti durante la fase di test, è stato battezzato Synthesizing Obama. È facile immaginarne un utilizzo pratico nell’animazione per il cinema e nel gaming, così come per l’interazione in tempo reale con modelli virtuali all’interno di un ambiente VR. Non è solo di un esercizio di stile: secondo Ira Kemelmacher-Shlizerman della Paul G. Allen School of Computer Science & Engineering, in futuro un sistema di questo tipo potrà tornare estremamente utile anche nell’ambito produttivo e in quello dell’educazione.
Una conversione realistica da audio a video ha potenziali applicazioni pratiche come il miglioramento dei meeting in videoconferenza o la possibilità, in futuro, di intrattenere una conversazione con un personaggio storico in un ambiente ricreato con la realtà virtuale, semplicemente partendo da un file audio.
L’altro lato della medaglia, quello che ha spinto a inserire “spaventoso” nel titolo di questo articolo, è legato ai potenziali usi impropri della tecnologia: la si immagini nelle mani sbagliate, dove diventerebbe uno strumento efficace per produrre false informazioni. Insomma, l’evoluzione delle fake news.
Come funziona?
Fortunatamente, si tratta di una tecnologia tanto complessa da poter difficilmente essere replicata dai non addetti ai lavori. Lo schema riportato di seguito mostra in pochi passaggi tutti gli step necessari per ottenere il risultato finale. Dapprima bisogna istruire una rete neurale con diverse ore di discorsi pronunciati dal soggetto (14 nel caso di Obama), così che il sistema di intelligenza artificiale possa associare a ogni singolo fonema un ben preciso movimento della bocca. Dopodiché, gli algoritmi si occupano del rendering del nuovo video, rendendo il passaggio da una posizione delle labbra all’altro del tutto naturale agli occhi di chi lo osserva.
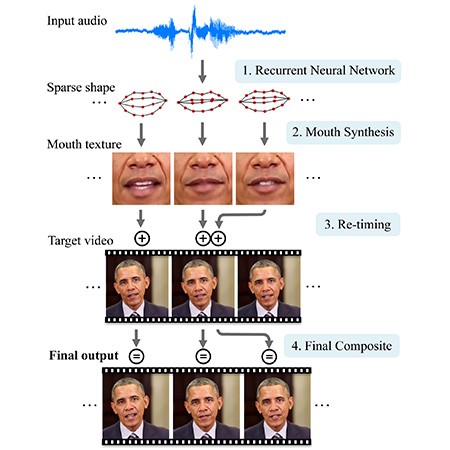
Il complesso funzionamento del sistema, basato sull’impiego di una rete neurale istruita mediante l’analisi di file audio, poi in grado di associare a ogni fonema un preciso movimento delle labbra generando infine il video
Dietro la ricerca ci sono nomi importanti: tra i finanziatori spuntano Samsung, Google, Facebook e Intel. I responsabili del progetto sono a conoscenza dei potenziali rischi connessi a un uso improprio del sistema e hanno tutte le intenzioni di scongiurarli, come sottolinea il professor Steve Seitz.
Non è possibile semplicemente prendere la voce di qualcuno e trasformarla in un video di Obama. Abbiamo deciso consciamente di impedire la possibilità di mettere le parole di qualcuno nella bocca di altri. Semplicemente, stiamo prendendo le parole reali che delle persone hanno pronunciato e le stiamo trasformando in un video realistico di quello specifico individuo.
/https://www.webnews.it/app/uploads/2025/04/flux_image_1212791_1744626268.jpeg)
/https://www.webnews.it/app/uploads/2024/10/ffbff933-17df-478e-9d1f-5503d03605bf.jpg)
/https://www.webnews.it/app/uploads/2024/10/357278.jpg)
/https://www.webnews.it/app/uploads/2024/10/28ebc471-1da5-41bb-b544-e96651c3f5ac.jpg)