/https://www.webnews.it/app/uploads/2011/03/google_docs.jpg "Google Docs, nuovi passi avanti dell'OCR")
L’Optical Character Recognition (OCR) è una tecnologia in grado di analizzare un documento o un’immagine digitale alla ricerca di caratteri testuali, offrendo poi la possibilità di ottenere un nuovo documento modificabile grazie ad un qualunque editor di testo. Da qualche tempo Google ha introdotto tale funzionalità in Docs ed ora annuncia l’arrivo del supporto a nuove lingue ed alcuni miglioramenti per quelle già disponibili.
Nella pagina per il caricamento di un nuovo file su Google Docs è presente un apposito campo da spuntare per attivare il riconoscimento dei caratteri. Una volta selezionato viene mostrato un menù a discesa dal quale scegliere la lingua più opportuna: oltre ad inglese, francese, italiano, spagnolo e tedesco da oggi è possibile sfruttare anche molte altre lingue europee ed asiatiche, come ad esempio il russo o il cinese semplificato (per un totale di 34 lingue). I miglioramenti riguardano anche l’importazione degli stili di formattazione del testo.
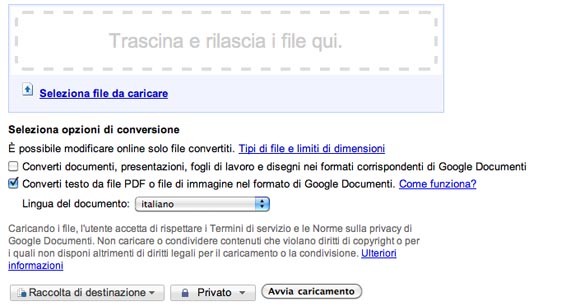
La schermata di caricamento file in Google Docs
Per ottenere risultati migliori il team di Google consiglia di utilizzare immagini o file PDF ad alta risoluzione, così da permettere allo strumento di analisi dei documenti di riconoscere maggiori dettagli. Una volta terminata l’operazione di conversione, il file di output è disponibile all’interno del proprio catalogo di documenti in Docs, con la possibilità di modificarlo tramite l’apposita utility di word processing fornita da Mountain View all’interno della suite per l’ufficio online.
La promessa degli ingegneri di “Big G” è quella di continuare i lavori per migliorare ulteriormente la serie di applicazioni con le quali Google punta a conquistare nuove fette di mercato a discapito dei più celebri nomi nel mondo dei software per l’ufficio. Oltre al supporto a nuove lingue gli addetti ai lavori intendono ottimizzare l’integrazione con quelle già attualmente disponibili, così da offrire uno strumento sempre più affidabile.
/https://www.webnews.it/app/uploads/2025/04/wp_drafter_1213218.jpg)
/https://www.webnews.it/app/uploads/2025/04/wp_drafter_1213200.jpg)
/https://www.webnews.it/app/uploads/2025/04/wp_drafter_1213202.jpg)
/https://www.webnews.it/app/uploads/2025/04/ubuntu.jpg)